Accelerating AI Journey
Fine-tune, deploy, and monitor LLMs for custom AI workflows.
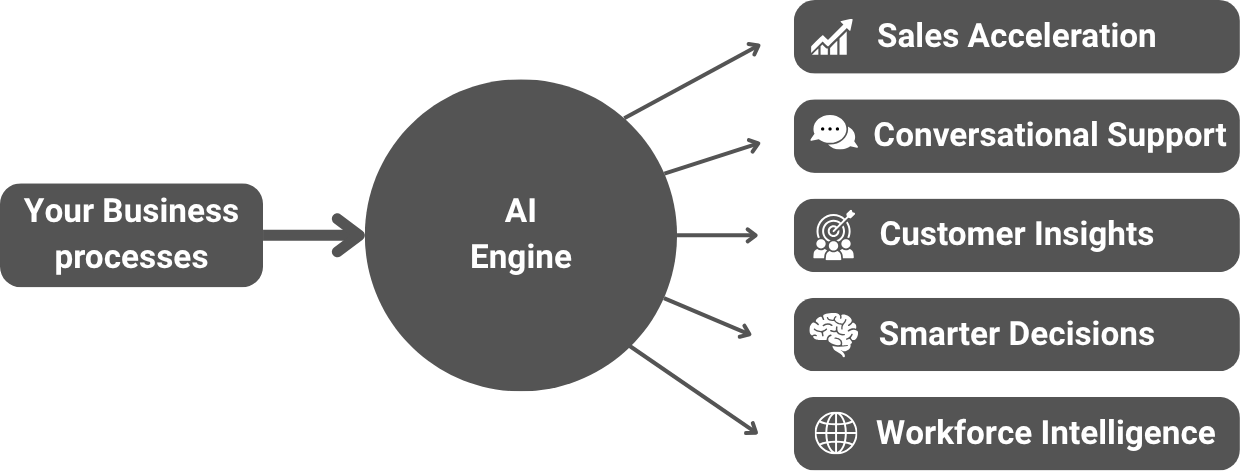
Tailoring smart Intelligence for driving impactful Results
Unlock peak performance for your most critical applications using domain-aware LLM optimization. From advanced RAG workflows to precision evaluation tools, we equip your models to our Engines, delivering impactful, production-grade outcomes.
Nainovate is excited to announce its membership in the NVIDIA Inception Program.
AI Workflows, from Prototype to Production
GenX delivers an end-to-end platform for building, deploying, and optimizing Large Language Models. From fine-tuning and RAG pipelines to real-time inference and RLHF, we provide every tool you need, to turn your ideas into production-ready AI applications at scale, with speed, and with precision.
🧩 Build It Yourself
Use our intuitive drag-and-drop interface to visually design, customize, and launch AI workflows in minutes. Whether you're mapping out a chatbot, automating document processing, or fine-tuning a language model, GenX makes it easy to build without writing a single line of code
🛠️ Done-For-You Service
Our team will design, build, and optimize your workflows for you-tailored to your business needs. Whether you're starting from scratch or scaling an existing process, GenX helps you move faster, smarter, and without complexity.
Product Tiers
Our GenX Engine is available in three powerful configurations:
N1
Core AI runtime & backend, organization & spaces setup, model, prompt & inference configuration, and task automation with AI agents.
N1 Pro
Includes all N1 features plus fine-tuning with adapters, hyperparameter optimization, and quantization. RLHF for preference collection, reward modeling, and behavior optimization.
N1 Max
Includes all N1 Pro features plus EDA, seed data generation, and data augmentation.
Platform Functionalities
We support cutting edge technologies that enhance AI capabilities and streamline workflows, we believe in continuous innovation as we adapt ourselves to how the AI regime changes. Some of our core functionalities include:
Design and deploy AI agent logic through a no-code visual interface. Create prompt chains, retrieval logic, and decision trees with drag-and-drop simplicity.
Connect internal docs, APIs, PDFs, and databases. Contexta handles chunking, embedding, and vector search to make your data usable for RAG pipelines.
Test LLM/SLM outputs using your real business cases. Modela helps benchmark accuracy, tone, latency, and cost to guide optimal model selection.
Supports real-time model inference on-prem, cloud, or hybrid using Triton, ONNX, or Hugging Face runtimes. Works seamlessly with both NVIDIA and AMD GPUs.
Capture user ratings, corrections, and business validations to enhance LLM output or fine-tune prompts. Human-in-the-loop made easy.
Track performance, latency, errors, and user interaction. Observa enables auditability and AI accountability.
Generate synthetic data for training and testing models used in Agents.
Enhance model training with synthetic data generation, ensuring diverse and comprehensive datasets.
Create high-fidelity synthetic data to fill gaps, boost diversity, and improve model robustness.
Usecases
Applications we've built
Our platform has transformed multiple industries by deploying intelligent AI chatbots that automate customer support. These real-world solutions have enabled organizations to improve operational efficiency, reduce costs, and deliver enhanced customer experiences at scale.
Recruitment Intelligence
We deployed an AI-driven recruitment assistant that analyzed over 100,000 resumes and matched candidates to roles with 85% accuracy. This cut hiring cycles by 40% and reduced HR costs by 30% across client platforms.
BOQ Intelligence
We implemented AI solutions that automated Bill of Quantities generation and validation across large-scale construction projects. This eliminated manual bottlenecks, improved accuracy by 90%, and saved over 2,000 man-hours annually.
Medical Intelligence
We built LLM-powered tools to extract insights from medical records and support clinical decisions, reducing document review time by 60%. This improved patient triaging and cut administrative costs in hospitals by 25%.
EDUtech Intelligence
We developed an AI-based answer evaluation system used by institutions to assess thousands of student responses. It improved grading consistency, reduced evaluation time by 70%, and enabled scaling across nationwide exams.
Real Estate Intelligence
We created AI tools that analyzed building plans and regulatory documents to estimate project costs and timelines. This reduced planning effort by 50% and helped firms deliver accurate insights within minutes instead of days.
Technical Overview
Our engine is built on a foundation of modularity, scalability, and efficiency. This architecture empowers developers and enterprises to build, scale, and optimize AI workflows with confidence.
Containerized Architecture

Adaptive Orchestration
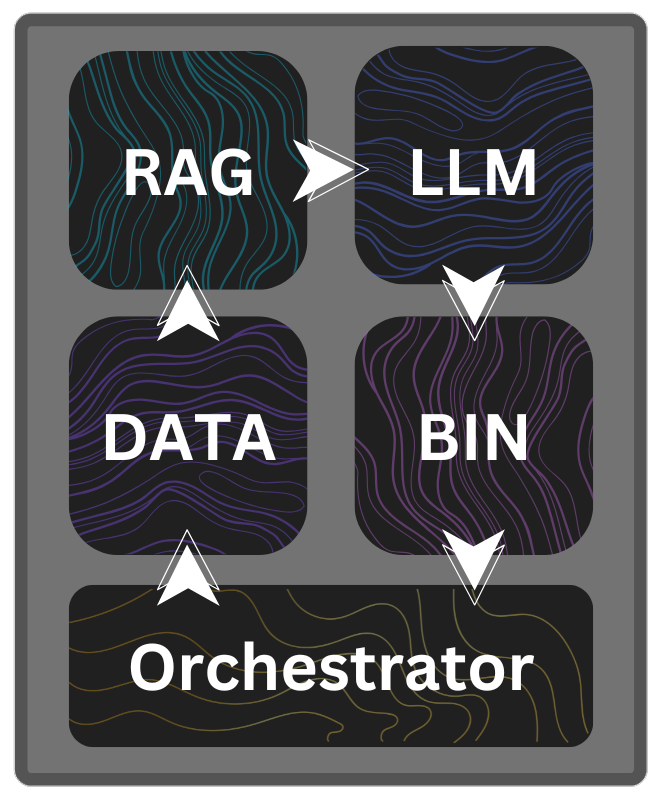
Data Abstraction Layer

Domain Agnostic
GenXflow is domain agnostic, empowering teams to create scalable AI workflows that seamlessly adapt to any industry or use case
Model Agnostic
Leverage the flexibility of both proprietary and open-source foundation models tailored to your use case and performance needs.
Hardware Agnostic
Deploy securely on your own servers or cloud-our hardware-agnostic stack supports ARM, x64, and runs across all major cloud providers and on-premise infrastructure.
What Our Clients Say

"Our team is thrilled to support your work."

"GenX streamlined our deployment and diagnostic processes like no other."

"The features are a game changer for our scale."

"GenX's customer support is top-notch. They helped us every step of the way."

"GenX is a reliable platfrom for fast, secure model pipelines. Simply unmatched."
"Our team is thrilled to support your work."
"GenX streamlined our deployment and diagnostic processes like no other."
"The features are a game changer for our scale."
"GenX's customer support is top-notch. They helped us every step of the way."
"GenX is a reliable platfrom for fast, secure model pipelines. Simply unmatched."
Get Started with GenX
Reach out today to discover how we can help transform your business.

Sneak Peek into GenX flow
GenX flow brings a visual edge to your AI stack-designed to orchestrate LLM workflows through an intuitive drag-and-drop interface. From fine-tuning to inference and beyond, it's a canvas built for creators, developers, and teams looking to move faster without losing flexibility. Welcome to a new era of AI design, reimagined.